
| CV | Google Scholar | Github | LinkedIn | |
Hi it's Yifan. I am a second-year CS Ph.D. student in Stony Brook University, advised by
Chenyu You.
My research interest broadly lies in Computer Vision, Machine Learning and Cognitive Science.
I am intrigued by the intersection of cognitive science and machine learning and I am committed to the development of reliable machine learning systems.
|
|
|
webpage |
abstract |
paper |
code |
While multi-step diffusion models have advanced both forward and inverse rendering, existing approaches often treat these problems independently, leading to cycle inconsistency and slow inference speed. In this work, we present Ouroboros, a framework composed of two single-step diffusion models that handle forward and inverse rendering with mutual reinforcement. Our approach extends intrinsic decomposition to both indoor and outdoor scenes and introduces a cycle consistency mechanism that ensures coherence between forward and inverse rendering outputs. Experimental results demonstrate state-of-the-art performance across diverse scenes while achieving substantially faster inference speed compared to other diffusion-based methods. We also demonstrate that Ouroboros can transfer to video decomposition in a training-free manner, reducing temporal inconsistency in video sequences while maintaining high-quality per-frame inverse rendering. |

|
abstract |
paper |
code |
Survival prediction using whole slide images (WSIs) can be formulated as a multiple instance learning (MIL) problem. However, existing MIL methods often fail to explicitly capture pathological heterogeneity within WSIs, both globally -- through long-tailed morphological distributions, and locally -- through tile-level prediction uncertainty. Optimal transport (OT) provides a principled way of modeling such heterogeneity by incorporating marginal distribution constraints. Building on this insight, we propose OTSurv, a novel MIL framework from an optimal transport perspective. Specifically, OTSurv formulates survival predictions as a heterogeneity-aware OT problem with two constraints: (1) global long-tail constraint that models prior morphological distributions to avert both mode collapse and excessive uniformity by regulating transport mass allocation, and (2) local uncertainty-aware constraint that prioritizes high-confidence patches while suppressing noise by progressively raising the total transport mass. We then recast the initial OT problem, augmented by these constraints, into an unbalanced OT formulation that can be solved with an efficient, hardware-friendly matrix scaling algorithm. Empirically, OTSurv sets new state-of-the-art results across six popular benchmarks, achieving an absolute 3.6% improvement in average C-index. In addition, OTSurv achieves statistical significance in log-rank tests and offers high interpretability, making it a powerful tool for survival prediction in digital pathology. Our codes are available at https://github.com/Y-Research-SBU/OTSurv. |

|
webpage |
abstract |
paper |
code |
Diffusion models have demonstrated impressive capabilities in synthesizing diverse content. However, despite their high-quality outputs, these models often perpetuate social biases, including those related to gender and race. These biases can potentially contribute to harmful real-world consequences, reinforcing stereotypes and exacerbating inequalities in various social contexts. While existing research on diffusion bias mitigation has predominantly focused on guiding content generation, it often neglects the intrinsic mechanisms within diffusion models that causally drive biased outputs. In this paper, we investigate the internal processes of diffusion models, identifying specific decision-making mechanisms, termed bias features, embedded within the model architecture. By directly manipulating these features, our method precisely isolates and adjusts the elements responsible for bias generation, permitting granular control over the bias levels in the generated content. Through experiments on both unconditional and conditional diffusion models across various social bias attributes, we demonstrate our method's efficacy in managing generation distribution while preserving image quality. We also dissect the discovered model mechanism, revealing different intrinsic features controlling fine-grained aspects of generation, boosting further research on mechanistic interpretability of diffusion models. The project website is at https://foundation-model-research.github.io/difflens. |
|
abstract |
paper |
code |
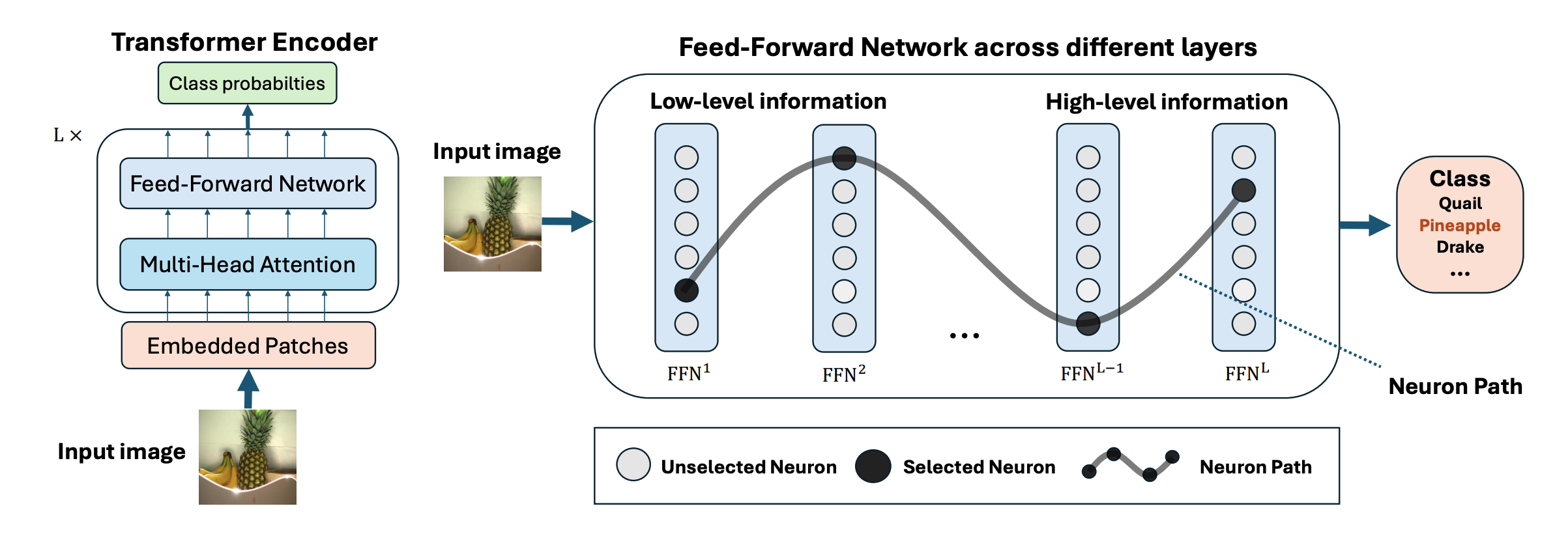
Vision Transformer models exhibit immense power yet remain opaque to human understanding, posing challenges and risks for practical applications. While prior research has attempted to demystify these models through input attribution and neuron role analysis, there's been a notable gap in considering layer-level information and the holistic path of information flow across layers. In this paper, we investigate the significance of influential neuron paths within vision Transformers, which is a path of neurons from the model input to output that impacts the model inference most significantly. We first propose a joint influence measure to assess the contribution of a set of neurons to the model outcome. And we further provide a layer-progressive neuron locating approach that efficiently selects the most influential neuron at each layer trying to discover the crucial neuron path from input to output within the target model. Our experiments demonstrate the superiority of our method finding the most influential neuron path along which the information flows, over the existing baseline solutions. Additionally, the neuron paths have illustrated that vision Transformers exhibit some specific inner working mechanism for processing the visual information within the same image category. We further analyze the key effects of these neurons on the image classification task, showcasing that the found neuron paths have already preserved the model capability on downstream tasks, which may also shed some lights on real-world applications like model pruning. The project website including implementation code is available at https://foundation-model-research.github.io/NeuronPath/. |
|
abstract |
paper |
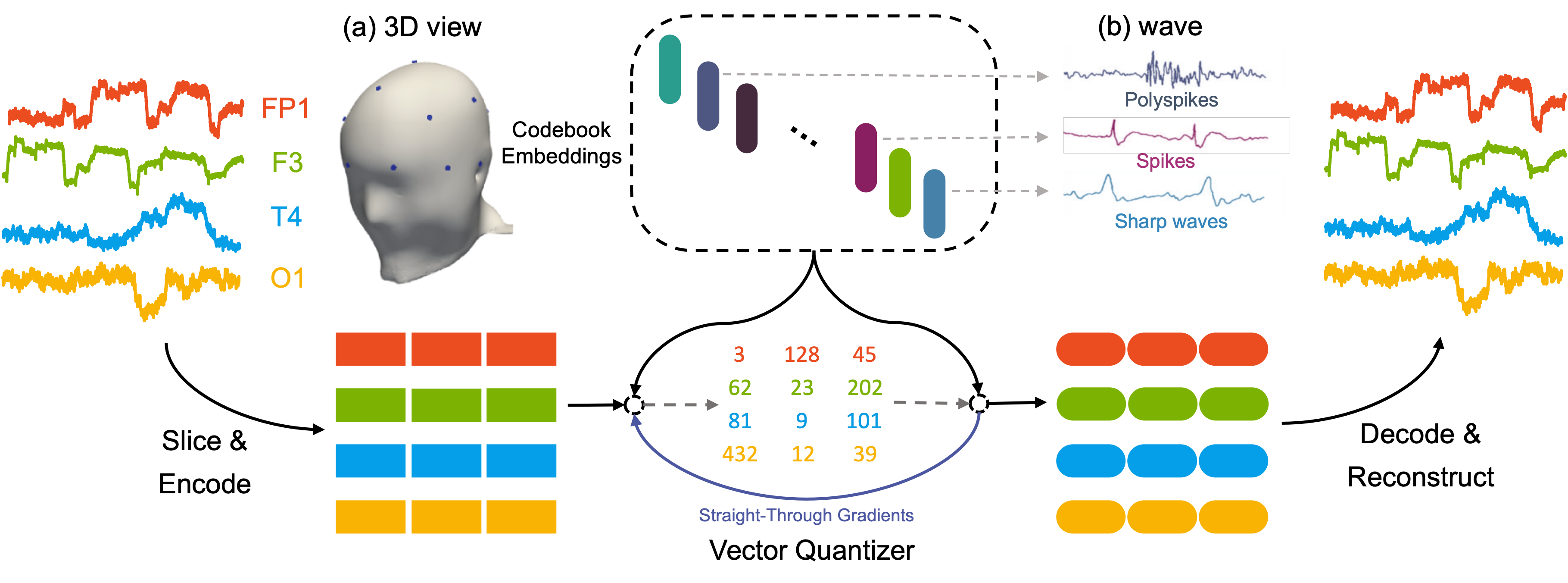
Self-supervised learning has emerged as a highly effective approach in the fields of natural language processing and computer vision. It is also applicable to brain signals such as electroencephalography (EEG) data, given the abundance of available unlabeled data that exist in a wide spectrum of real-world medical applications ranging from seizure detection to wave analysis. The existing works leveraging self-supervised learning on EEG modeling mainly focus on pretraining upon each individual dataset corresponding to a single downstream task, which cannot leverage the power of abundant data, and they may derive sub-optimal solutions with a lack of generalization. Moreover, these methods rely on end-to-end model learning which is not easy for humans to understand. In this paper, we present a novel EEG foundation model, namely EEGFormer, pretrained on large-scale compound EEG data. The pretrained model cannot only learn universal representations on EEG signals with adaptable performance on various downstream tasks but also provide interpretable outcomes of the useful patterns within the data. To validate the effectiveness of our model, we extensively evaluate it on various downstream tasks and assess the performance under different transfer settings. Furthermore, we demonstrate how the learned model exhibits transferable anomaly detection performance and provides valuable interpretability of the acquired patterns via self-supervised learning. |

|
webpage |
abstract |
paper |
code |
Human affect recognition has been a significant topic in psychophysics and computer vision. However, the currently published datasets have many limitations. For example, most datasets contain frames that contain only information about facial expressions. Due to the limitations of previous datasets, it is very hard to either understand the mechanisms for affect recognition of humans or generalize well on common cases for computer vision models trained on those datasets. In this work, we introduce a brand new large dataset, the Video-based Emotion and Affect Tracking in Context Dataset (VEATIC), that can conquer the limitations of the previous datasets. VEATIC has 124 video clips from Hollywood movies, documentaries, and home videos with continuous valence and arousal ratings of each frame via real-time annotation. Along with the dataset, we propose a new computer vision task to infer the affect of the selected character via both context and character information in each video frame. Additionally, we propose a simple model to benchmark this new computer vision task. We also compare the performance of the pretrained model using our dataset with other similar datasets. Experiments show the competing results of our pretrained model via VEATIC, indicating the generalizability of VEATIC. |
|
|
Template from this awesome website. |